Datamängd: Träningsdata för HTR-modeller
Länk till träningsdatat på HuggingFace: Training data for Swedish Lion Libre
Licens: CC0
Citering: Swedish National Archives (2024). Training data for HTR models at the Swedish National Archives (Swedish Lion).
Publicerad: 2024
Uppdaterad: –
Detta dataset omfattar en samling noggrant manuellt transkriberade (avskrivna) och segmenterade (uppdelade) texter från arkivhandlingar på Riksarkivet. Texterna har använts som träningsdata i framtagande av Riksarkivets AI-modell för transkription av handskriven text på svenska.
Swedish Lion Libre och dess associerade modeller för region- och linjesegmentering på HugginFace
The Swedish Lion I i plattformen Transkribus
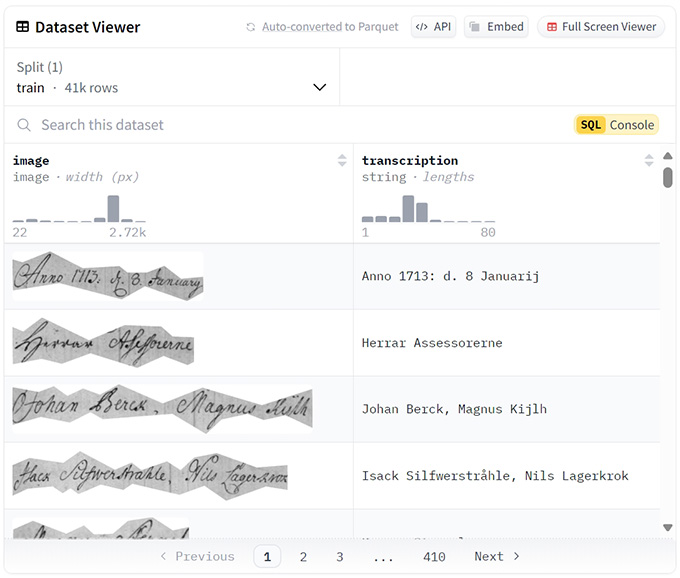
Skärmbild från HuggingFace där träningsdatasetet är publicerat.
Datasetet innehåller totalt 565 146 rader text i dataformatet
Parquet. Arbetet med att skapa träningsdata är utfört i
Transkribus
och är en del av Riksarkivets samarbete med
READ-COOP SCE. Arkivhandlingarna som detta träningsdataset är skapat ifrån är daterade från 1600-talets första hälft fram till sekelskiftet 1900.
Läs om Parquet på Wikipedia
Till Transkribus
Till READ-COOP SCE
Träningsdata är skapat av medarbetare på Riksarkivet, av Riksarkivet arvoderad personal, samt av frivilliga medborgarforskare. Arbetet har delvis skett inom det av Vinnova finansierade projektet "Maskintolkning av handskrivna källmaterial" och det av Riksantikvarieämbetet finansierade projektet "Transkriberingsnod Sverige – maskintolkning och medborgarforskning kombinerade".